 Nicolas Belissent · · 6 min
Nicolas Belissent · · 6 min 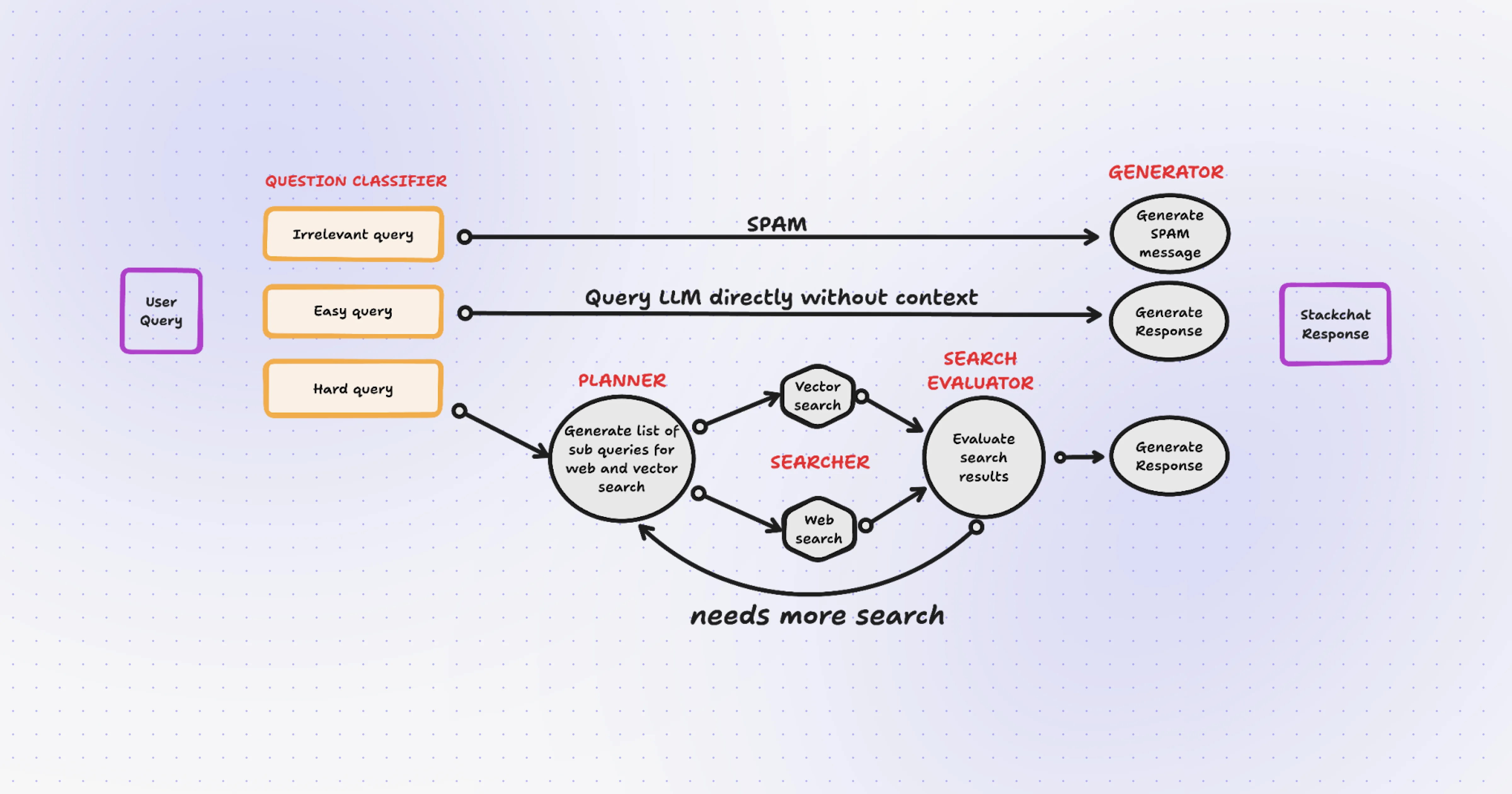
Tools not Rules
Table of Contents
Creating effective AI agents presents significant technical hurdles. Users expect answers to their questions, sources for further exploration, consistent output formatting, and smooth streaming. Though these seem straightforward, they create intricate engineering challenges.
During development, the team recognized limitations within pure rule-based approaches, even structured frameworks like LangGraph. We explored Model Context Protocol (MCP) to address specific obstacles.
Understanding the Current State
StackOne developed StackChat, a retrieval-augmented agent providing precise API information by dynamically accessing our proprietary knowledge base. Currently used internally by solutions engineers, sales, and integrations teams, it streamlines technical documentation access.
StackChat employs a Directed Acyclic Graph (DAG) within AI pipelines — comparable to an assembly line where each node performs specialized tasks sequentially.
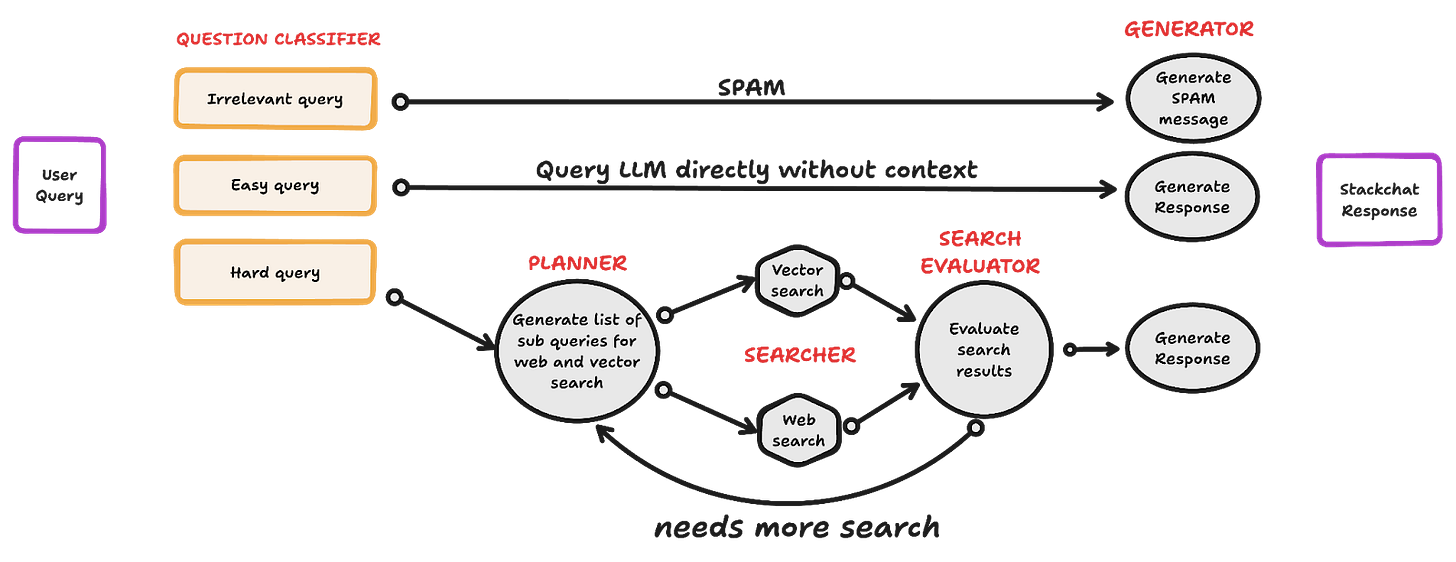
Current Architecture Components
- Question Classifier: Routes queries as irrelevant, easy, or complex
- Planner: Generates sub-queries for complex requests
- Searcher: Executes parallel search paths (vector and web)
- Search Evaluator: Reranks results before response generation
- Feedback Loop: Triggers additional searches when needed
The Strengths
DAG architectures excel at structured workflows with defined steps:
- Precise information flow control
- Model selection optimized per node
- Comprehensive logging at each stage
- Deterministic, reproducible behavior
- Effective safety guardrails
- Strictly enforced response formatting
However, limitations emerged. Teams found themselves endlessly tweaking prompts and optimizing retrieval metrics without clarity on effectiveness. Advanced reasoning models like GPT-4.1, Claude Sonnet 3.7, and Gemini 2.5 Pro revealed that stepwise architectures may underutilize their reasoning capabilities.

The Pain Points
Unpredictable Query Needs
The rigid DAG system couldn’t adapt to varying information requirements. Simple questions triggered excessive searches while complex ones lacked sufficient context. The planning component made poor judgments about search depth.
The Reranking Problem
Evaluating reranking quality for complex API specifications proved challenging. Finetuning attempts yielded poor results. Questions arose about chunking strategies for JSON documents and their effectiveness.
Prompt Engineering Challenges
Managing prompts across multiple stages created maintenance burdens. The prompt library grew huge with numerous edge cases and conditional logic.
Architectural Rigidity
The system couldn’t dynamically decide when to query more or less. Behavior remained heavily influenced by the examples provided in the prompt.
Introducing Model Context Protocol
MCP takes a fundamentally different approach. Rather than fixed steps, MCP empowers the model (or agent) itself to determine what information it needs and when. The model receives tools and autonomy to decide their usage based on query requirements.
The stackchat-mcp toolset includes:
- Keyword search
- Vector search
- cURL tool for direct API interaction
- OpenAPI specification summarizer
- Web search
- Provider metadata tools
- YAML validation
- Status code explanations
Execution flow emerges dynamically based on the model’s assessment.
Advantages of Model Context Protocol
Dynamic Tool Usage
Having the client agent determine which tools to use and when to use them creates a more adaptive system. The elimination of rigid query planning proves valuable when optimal tool sequences aren’t predetermined.
Natural Relevance Assessment
By allowing the same intelligence to evaluate and generate responses, the model can make nuanced judgments about relevance difficult to capture in separate systems.
Architectural Simplicity
Eliminating classification and planning stages reduces complexity. Adding new capabilities now means simply adding new tools, enabling faster iteration without rewriting orchestration logic.
Limitations of Model Context Protocol
Decreased System Ownership
With MCP, the model controls the entire interaction flow on the server. This sacrifices control over response generation. The ultimate decision authority rests with the model, creating unpredictability in edge cases.

Limited Custom Formatting
MCP offers less control over response formatting since models create entire responses post-tool use. Teams depend entirely on the model’s natural formatting abilities, especially for citations and API responses.
Reduced Logging and Observability
The protocol hides reasoning steps inside the model on the server. While tool calls are logged, we can’t see why tools were chosen or how results were used. Teams must analyze patterns rather than directly observe decision processes.
Conclusion
The tools-based approach enabled easier team interaction, improvements, and more effective usage. While MCP isn’t perfect, it addressed the fundamental paradox of our DAG architecture — the uncomfortable combination of unpredictability and rigidity.

Both approaches provide value in different contexts. DAGs excel when requiring precise control, consistent formatting, and comprehensive logging. MCP excels with unpredictable queries requiring dynamic information gathering. Rather than competing, they’re complementary tools in our AI engineering toolkit.