 Will Leeney · · 4 min
Will Leeney · · 4 min 
Building an Eval-Driven AI Feature at StackOne
Table of Contents
StackOne connects to hundreds of providers through one API. When errors occur — expired keys, missing scopes, unsupported actions — the system surfaces raw provider errors. These errors reference provider-specific concepts that don’t help users in the StackOne dashboard.
As an AI Engineer with a PhD studying evaluation best practices, I spent my first month building an AI agent to translate provider errors into clear resolution steps. The key approach: starting with evaluations from day one.
Start with the Problem, Not the Solution
Before coding, I interviewed Bryce, a solutions engineer, to understand the manual error resolution process. Users encounter errors in three locations: account linking, account status, and connection logs. Solutions are documented across various guides.
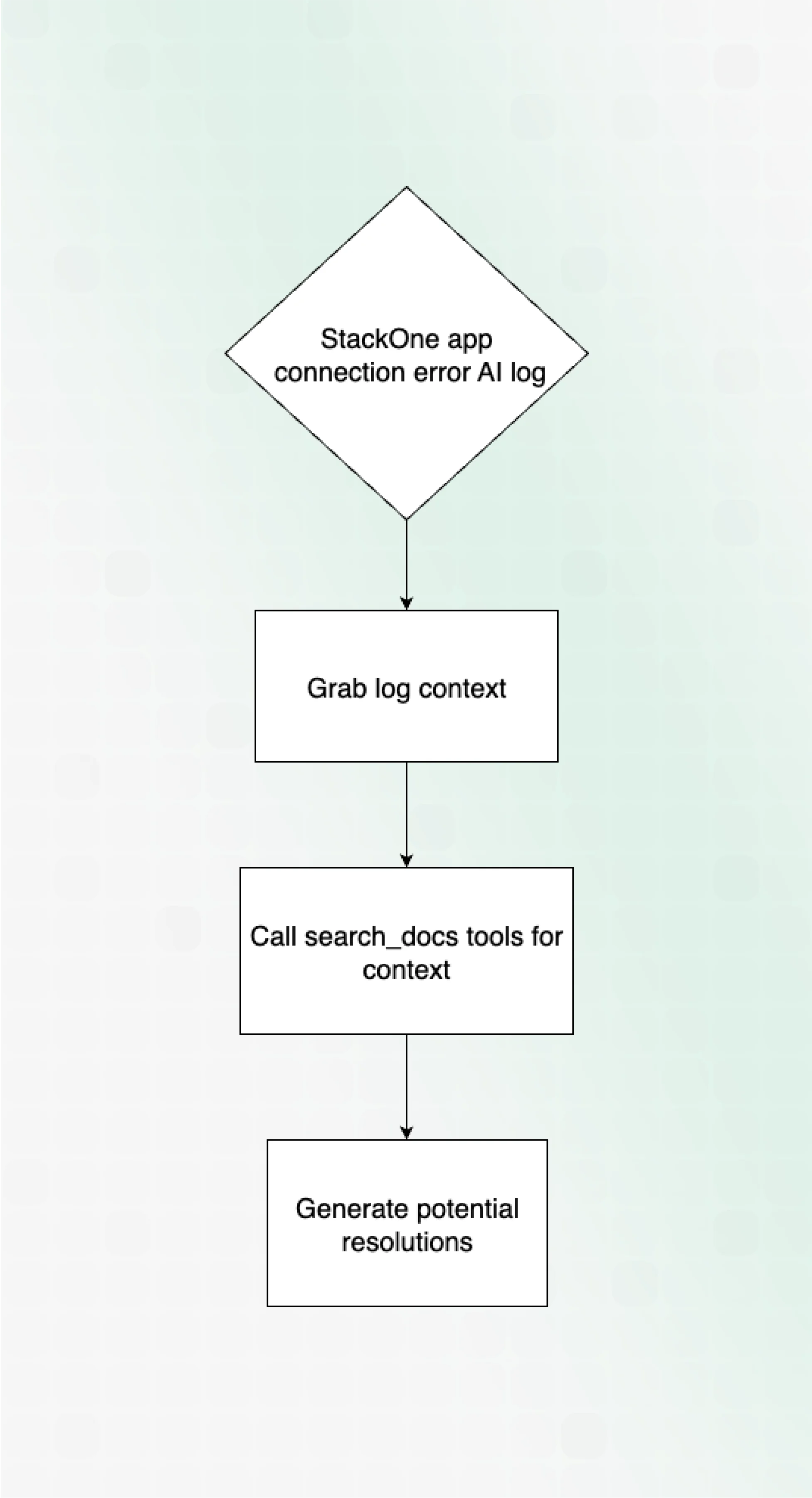
The goal was straightforward: automatically search documentation and generate resolution steps. I resisted building a complex RAG system with time-series analysis. Instead, I sketched the simplest possible flow and committed to shipping first and improving later.
Build Tools, Test Early
The system’s core uses Claude with custom tools for documentation searching. The tool registration includes:
{
"name": "grab_error_code_guide",
"description": "Fetch API error codes from StackOne",
"input_schema": {
"type": "object",
"properties": {},
"required": []
}
}
A significant efficiency gain came from exposing all documentation as plain .txt and .md files at docs.stackone.com/llms.txt. This eliminated scraping and complex parsing work.
Five tools were developed:
grab_error_code_guide— Fetches error code referencegrab_troubleshooting_guide— Fetches troubleshooting documentationsearch_stackone_docs— Searches all documentationsearch_provider_guides— Searches provider-specific documentationsearch_docs— Vector search using Turbopuffer database
Extracting context from messy logs proved challenging. The solution used Pydantic for structured outputs with gpt-4o-mini to extract necessary fields for resolution.

Evals Drive Everything
This is where most AI features fail: shipping without verification of functionality.
The approach taken:
- Connected the Lambda function to LangSmith for full observability
- Created real errors in the development environment
- Ran them through the resolution agent
- Manually corrected outputs in LangSmith to create a golden dataset
- Used this as an evaluation benchmark
Every prompt change could be measured against this benchmark, eliminating guesswork about whether modifications helped or hurt performance.
Ship with Feedback Loops
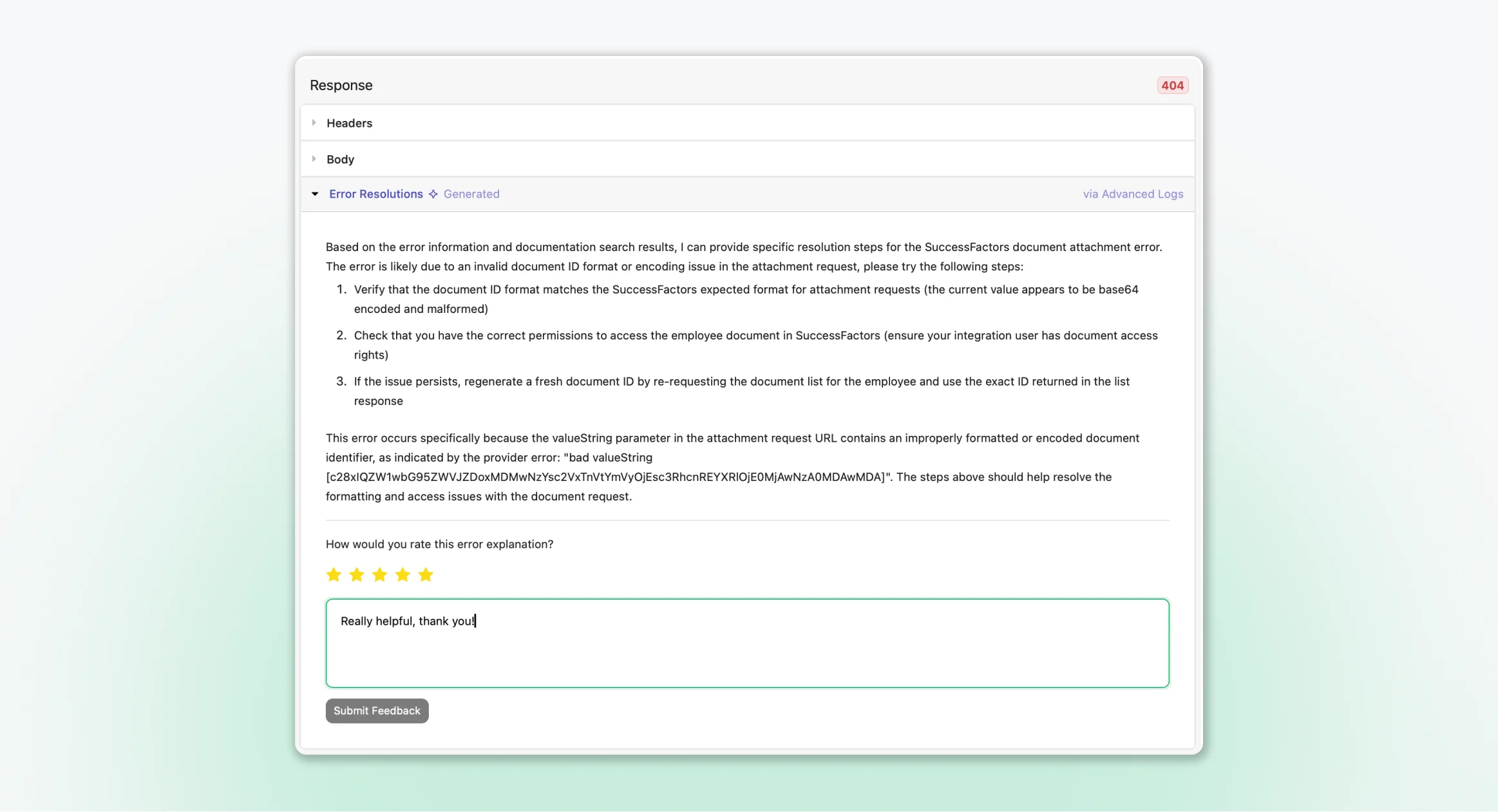
We recognized customers could provide feedback on resolution quality post-launch. This real-world data could enhance the evaluation database.
The feedback system works through:
- Each resolution receives a unique LangSmith trace ID
- Users rate resolution quality
- Feedback flows back to LangSmith, expanding the eval dataset
- Real-world usage continuously improves the model
This creates a virtuous cycle: ship, collect feedback, improve evals, enhance prompt, ship better version.
The Technical Stack
- Lambda — Hosts the resolution agent
- LangSmith — Tracks generations and builds eval datasets
- Logfire — Monitors LLM performance
- DataDog — Tracks execution metrics
- PostHog — Measures feature usage
- CDK — Manages infrastructure as code
The frontend integration was straightforward, exposing a single endpoint /ai/resolutions that accepts error logs and returns resolution steps.
Lessons Learned
- Start with evals, not features — Without evaluation, development proceeds without proper guidance
- Ship the simplest version first — The initial RAG design would have required months; the basic version shipped in weeks
- Real usage beats synthetic data — Customer feedback creates superior evals compared to test data
- Tools are just functions — LLM tool design shouldn’t be overcomplicated; they’re Python functions with JSON schemas
The feature progressed from concept to production in one month, not through rushing but by focusing on what mattered: knowing whether it actually worked. Evaluations aren’t afterthoughts in AI development — they’re foundational.